
About our articles and guides
In our work on 100+ games with 80+ game teams, there are some challenges that we encounter again and again. Over time, our experiences naturally evolve into generalizable best-practices.
In these articles, I attempt to document these best-practices and make them available to everyone!, not just the few core clients that we serve.
About this article
The focus of THIS article series will be Split-Testing (also known as A/B Testing), in service of KPI improvement for live, mobile free-to-play games.
As with many specialized topics, split-testing is covered in countless articles and guides at a superficial level, but in-depth coverage of the topic is surprisingly scant. Most in-depth articles seem to cater to online marketers and conversion rate optimization for landing pages or ads. Compared to conversion testing, mobile game feature testing is typically more complex, has different pitfalls and requires a different approach. That approach is the focus of this article series. This article series is written for mobile game product leaders, and should help empower them to split-test product changes in any area of interest: features, tuning, pricing, art, merchandising, and UI/UX.
This is not light reading material. This article will likely bore most to tears 😭, save for the relatively few, fellow mobile game product managers out there.
For lighter reading, check out one of our more popular articles, like “How to Fail at Mobile Games!”
For those still with us…
To do the topic justice, we will need to cover experimental design and statistical analysis in some depth, as these topics are the most opaque, least-well understood, and most likely to trick us into drawing the wrong conclusions from our tests. As a product manager (and not a statistician) by trade with over 600 (product and app store) split-tests under my belt, I have intimate experience with being on the wrong side of these mistakes.
While I hope that you find this article useful, please don’t hesitate to comment or offer advice or critical feedback. I invite statisticians out there to question (and help improve) our methodology. Because we (at Turbine) run hundreds of product split tests per year, I will update this article as our approach continues to mature, and will post to announce any updates.
Of course, the best way to learn our split-testing methodology is by doing it with us, on your own live game! While doing so, you’ll be improving product retention and monetization – 20-400% ARPU lifts are typical. DM me if interested.
With that said, let’s dig in.
What IS Split-Testing?
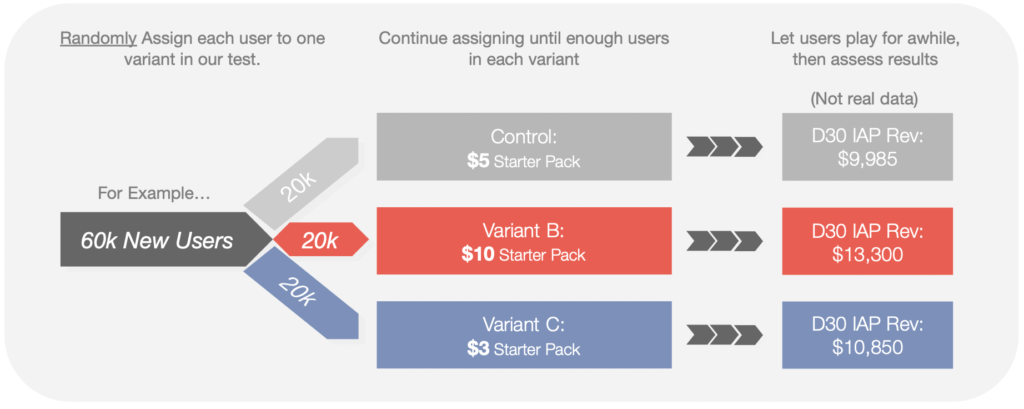
Split-Testing is an experimental method where we do the following:
- Show different versions of a product to different groups of users, then…
- Measure performance of the groups (on key metrics), then…
- Use statistical tools to predict which version will perform better for ALL users…
- with specific, measurable degrees of certainty.
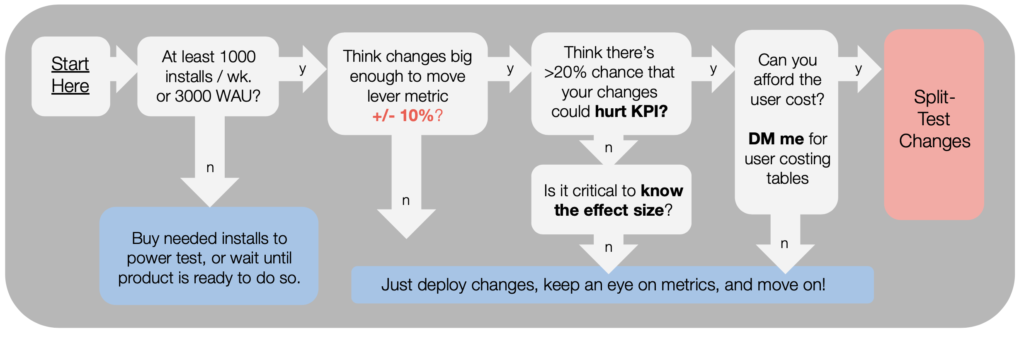
WHEN Should We Split a Game Change or Feature?
- Split-testing product changes (changes to the game itself, not just the ads or app store assets) is only realistic for live products with significant user volume (say, 1,000+ installs per week or 3,000+ WAU).
- Even then, because split-testing requires significantly more effort and attention than simply releasing features normally, it should be used judiciously. It is not a free ride.
- When it comes to product changes, split-testing is generally worth considering when you have reason to believe the impact of your changes will be large, and risky (impact could be negative for some of your variants).
For more detail, this flowchart below may be helpful.
What metric(s) should we target?
The short answer? (1) A lever metric that the experiment targets directly (defined below), (2) dX retention (X varies with experiment, as we’ll later discuss), and (3) dX ARPU as a proxy for LTV.
The slightly longer answer:
Ultimately, the goal of most (if not all) experiments is to increase player LTV.
Experiments targeting retention do so with the intent to increase LTV. Without driving LTV, retention’s impact on business outcomes is quite limited (aside from hypothetical virality and some impact on appstore search rank).
The relationship between retention and LTV is complicated and inconsistent. Sometimes, improving LTV comes at the cost of retention, e.g. when tightening an economy or showing ads more frequently. Conversely, making an economy more generous can improve retention, at the cost of LTV.
For this reason, we recommend always evaluating dX retention and dX ARPU as primary KPI for any split-test.
Realistically, for some experiments, you won’t budget enough users to power statistically significant IAP results (doing so is expensive), but that doesn’t mean you should ignore dX ARPU data. You might still learn something and, given the primacy of ARPU for business outcomes, I’d argue that it always deserves consideration.
Besides LTV (ARPU as proxy) and retention, most experiments need a third metric, which we call the lever metric. This is the metric the experiment directly manipulates, with the hopes of having downstream impact on retention and/or LTV.
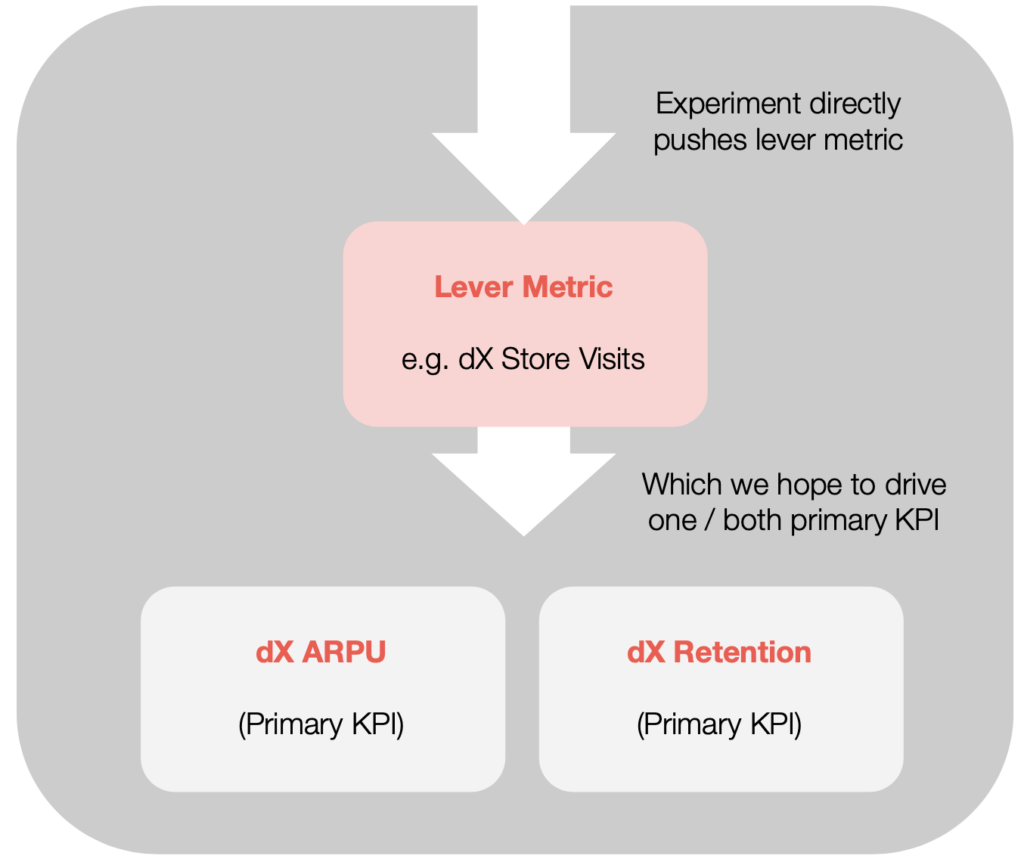
A simple example: imagine an experiment testing the placement of a daily reward in the game store, for purposes of increasing daily store traffic, and IAP LTV as a byproduct. In this experiment, an appropriate lever metric might be total store visits by dX, or average unique daily store visitors by dX.
And, of course, the two other primary metrics for evaluation would be dX ARPU and some retention checkpoint (D14, D30, etc.), as appropriate for the experiment.
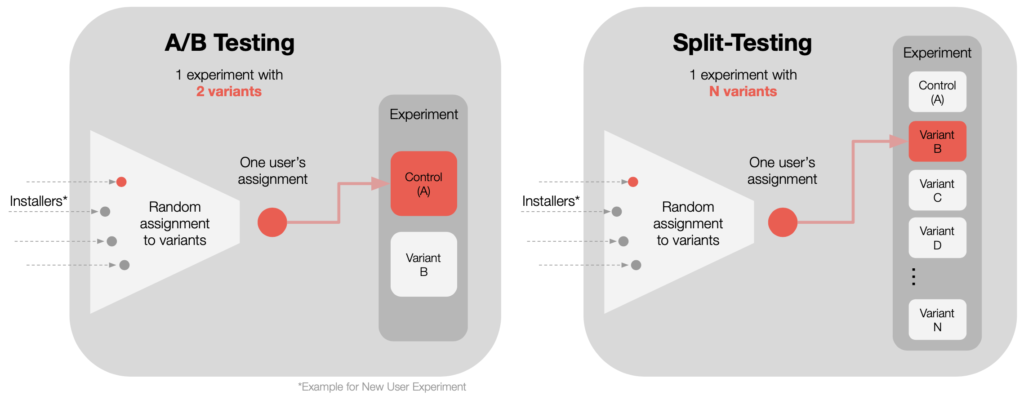
On Terminology: A/B Testing or Split-Testing?
These terms are nearly identical. ‘A/B Testing’ is a more popular term, but often implies an experiment with only two variants: A and B.
The term ‘split-testing’ allows for any number of variants, and is therefore our preferred term.
Stacked Split-Testing, and Siloed vs. Blended approaches
In our work with clients, Turbine nearly always ‘stacks’ multiple split-tests, run in parallel, to get more experiments done in less time. There are two different ways to approach this: Siloed testing and Blended testing.
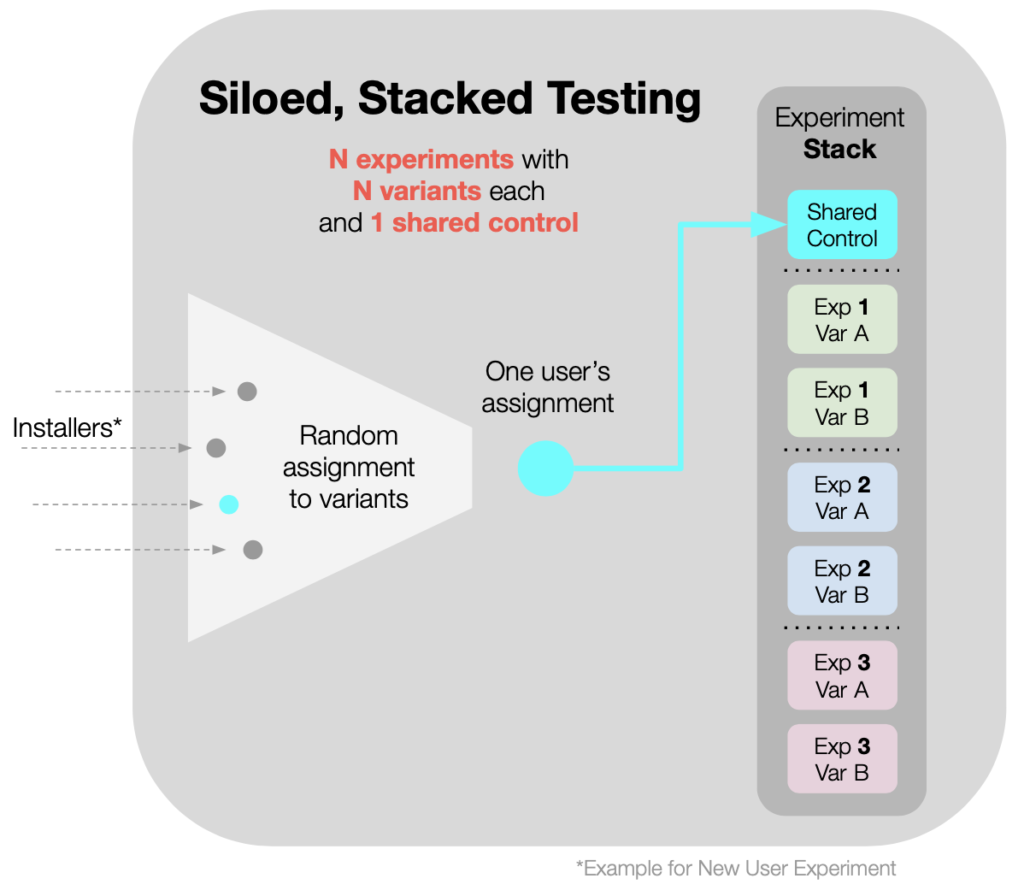
Siloed Split-Testing (in stacks) is our preferred term for
- running a stack of several experiments concurrently…
- where the experiments have a single, shared control group, and…
- where each user enrolled is subjected to only one of the experiments.
Benefits of ‘Siloed-Stacked Testing:’
- Practically speaking, stacking experiments gets more experiments done, in less time.
- Sharing a control group across multiple experiments reduces user costs.
Analysis: During analysis, we compare all variants to the shared control using our statistical tools, which we’ll discuss at length in our next article.
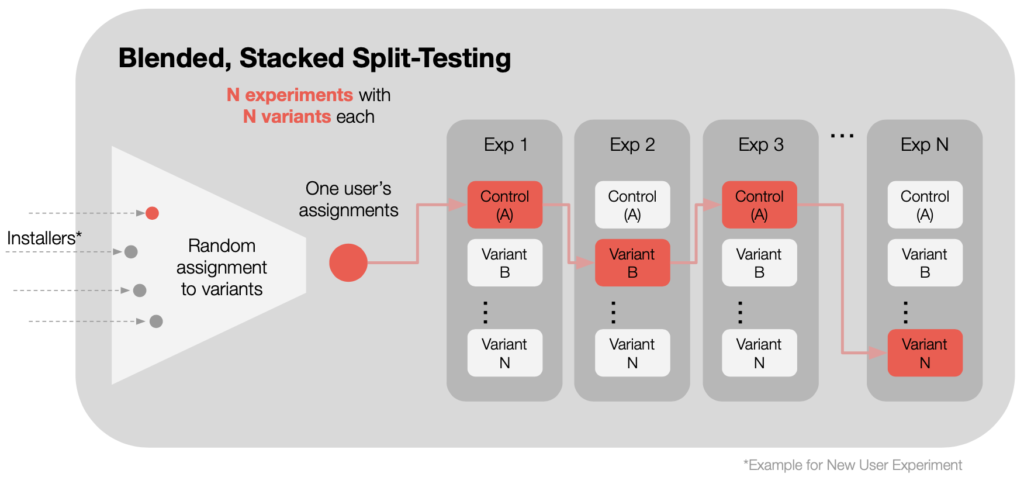
Alternatively, Blended Stacked Split-Testing is our preferred term for
- running a stack of several experiments concurrently…
- where each experiment independently assigns its own control group, and
- where each user is simultaneously enrolled in ALL experiments in the stack.
Benefits of Blended Stacked Testing:
- Stacking gets more experiments done in less time.
- You can assess intersections of winning variants, before deployment.
- You can enroll many more users into each experiment than is possible with siloed stacking. In most cases this benefit can outweigh any additional noise caused by blending.
Analysis: During analysis, we assess each experiment’s variants individually vs. their own control.
After finding winning variants across experiments, and before rollout, we can look at the intersections of these winners as a gut check for any negative interaction effects.
Below is an example, showing how a single user is randomly placed into one variant for every experiment in the stack. Below, the user shown is placed in the control groups for experiment 1 and experiment 3, but is exposed to variants in Experiment 2 and Experiment N.

Answer: According to our research and experience, no. With random assignment of users to experimental variants, and with each experiment only modifying / controlling one variable (while letting all others remain random), the background ‘noise’ of player differences arising from other experiments (1) approaches zero impact with large enough sample sizes, (2) isn’t materially different from the myriad, random differences already present (player play preferences, spend preferences, device type, geography, and numerous others), and (3) is usually offset by the benefit of having many more users enrolled in each experiment.
That said, some experiments can produce noisy results when blended, e.g. three experiments all targeting the same narrow metric like D0 IAP CV. This can be countered by adding more players to the stacked experiment, or un-stacking them.
Finally, be careful not to blend experiments whose changs are mutually exclusive (i.e. where the winners of each experiment can’t ultimately be combined). Mutually exclusive product changes should either be siloed, or made independent variants of a single experiment.
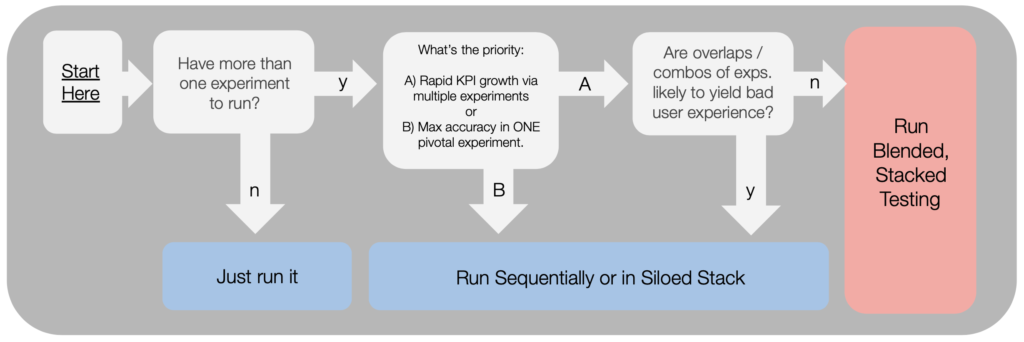
When should we use Blended, Stacked Testing?
At Turbine, we used to run Siloed Stacked tests exclusively. However, over the last 12 months, we have gradually learned to embrace Blended Stacked testing.
As of today, we have become big fans, primarily due to the large gains in efficiency, but also the added ability to catch unexpected interaction effects.
For more details, here’s our current thinking regarding which approach to use:
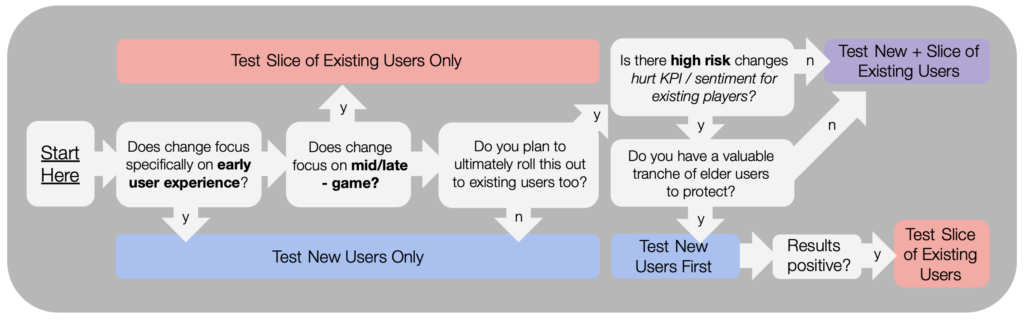
Should we test New or Existing users?
For games with existing, valuable player-bases, we usually err on the side of caution and test new users first, and then existing.
However, if we know that risk to existing users is low, we will likely opt to test on both in parallel, for efficiency.
Here’s a flowchart of our thought process for new vs. existing user testing:
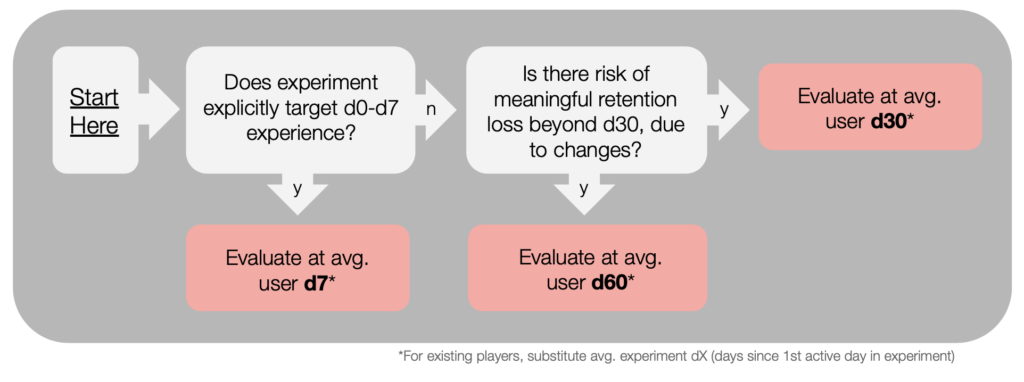
How long should we run experiments?
Turbine usually assesses experiments at average user d30 (for new installers) or average user ‘test-d30’ (for existing users: 30 days after the first day each user has their first active day within the experiment). When we need to be extra careful about retention risk, we will run to average user d60.
Note that ‘average user d30’ means that the average player age in the cohort is 30 days from install. Because installs occur over a period of time, some users will of course be younger, and some older, at the time of analysis.
For more detail, a flowchart:
How many users do we need?
This is a critical question when considering test structure, and one of the areas where mistakes are most common.
Getting this right is a question of statistics, so to do it justice we will circle back after covering the statistical tools used to analyze split test results.
We’ll cover this topic in the next article in the series.
Should we exclude any users?
A critical step in experiment design is the definition of inclusion criteria: what users need to do to ‘qualify’ for inclusion in final analysis, and which users will be excluded.
As a simple example, imagine you are testing the impact of a change to a screen.
It obviously wouldn’t make sense to include in the final analysis users who never reached or saw the screen in question! Including them would only add truly random noise to your data, and weaken the ability of your experiment to isolate the impact of your specific changes.
Lastly, inclusion criteria should be defined before the experiment starts, so that you aren’t later tempted to fit the rules to the data.
Most Common Split-Testing Mistakes
Last but not least, here are the mistakes we see most commonly, both in test structure and analysis (covered in next article):
Structural mistakes
- Split-testing too early in the product lifecycle, when you should be ‘building’ (adding well-proven features) instead of ‘optimizing’
- Split-testing product changes that do not need testing (just make the change!)
- Testing changes that are too small to make a measurable difference, e.g. the mythical ‘button color’ experiment 😅
- Assigning too few users to an experiment, particularly for IAP testing
- Not instrumenting lever metrics to aid in validation of results, and just relying on a tentpole KPI like ARPU
- Not blending and stacking experiments when reasonable
- Not doing proper QA on the experiment setup
- Accidentally exposing elder / existing users to an experiment intended for new users 😖
Analysis mistakes
- Relying on black-box systems (like web-based tools) without fully understanding / doing the statistical analysis yourself
- Relying simply on aggregate metrics (like ARPU) without statistical significance testing and other tools
- Not committing to a specific date to measure & determine results (e.g. D30); calling the experiment on a random date when you see the result you want 😅
- Optimizing for statistical perfection (99% confidence!) over speed and volume of high-ROI tests. This is likely to happen if you let your data scientists drive the process 😇
Key takeaways from Part 1:
- A/B Testing and Split-Testing are essentially synonymous, but we prefer the latter.
- Split-Testing is appropriate for teams with live products that have user volume (at minimum I’d say 1000+ weekly installs or 3000+ WAU (for existing user tests).
- Multiple experiments can be ‘stacked’ on top of each other and run in parallel for efficiency gains, either in ‘Siloed’ or ‘Blended’ fashion. We generally prefer blended, stacked testing for maximum efficiency.
- Experiments can target New Users, Existing Users, or both simultaneously, depending on how careful we want to be to protect existing users’ experience
- We generally recommend performing analysis at avg. user D7, D30 and/or D60, and deciding in advance which age will be decisive.
In the next article in this series, The A/B Testing Playbook for Mobile Games, Part 2: Statistical Significance Testing, we’ll go deep on statistical tools for test analysis, and answer some tricky but frequently asked questions.
PS: The best way to learn our full split-testing methodology is by doing it for real, with us, on YOUR live game! Turbine’s monetization growth service focuses on rapid-split testing, and typically yields ARPU gains of 20-400%. Our approach is informed by work with over 80 F2P game teams and over 600 experiments. If interested to learn more, DM me!
If you enjoyed this article, you might also like my series on F2P IAP Merchandising best practices:
- The IAP Merchandising Playbook, Part 1: Special Offers That Sizzle
- The IAP Merchandising Playbook, Part 2: Visual Hierarchy
- The IAP Merchandising Playbook, Part 3: MVP Store Design
Need help with your game? Email me at matt@turbine.games, or book a time on my calendar.